Cách cấu trúc và tái sử dụng câu lệnh SQL
--

Vấn đề
SQL là ngôn ngữ chính để làm việc với cơ sở dữ liệu có cấu trúc. Tuy ngôn ngữ này dễ học và dễ sử dụng để truy vấn, nó cũng có nhiều điểm bất lợi khi bạn phải sử dụng và quản lý một hệ thống lớn với nhiều câu lệnh.
Không dễ dàng sử dụng lại
Ví dụ khi muốn lấy thông tin từ bảng booking, tôi phải đi kèm một điều kiện where tương ứng. Nếu bảng booking này xuất hiện trong nhiều câu lệnh query, tôi sẽ phải viết lặp lài điều kiện này. Khi logic lấy từ bảng booking thay đổi, tôi sẽ phải tìm và thay đổi toàn bộ logic này ở tất cả các query có sử dụng bảng booking.
Logic không tập trung
Nhìn chung logic các chỉ tiêu sẽ lấy rải rác ở nhiều câu lệnh SQL khác nhau thay vì tập trung ở một nguồn duy nhất. Điều này gây khó khăn cho người mới tiếp cận cơ sở dữ liệu hiện tại và khó cho việc bảo trì câu lệnh SQL.
Hẳn nhiên SQL được tạo ra để truy vấn chứ không được tạo ra để có thể dễ dàng quản lý và cấu trúc. Tuy nhiên việc quản lý và bảo trì logic code cũng rất quan trọng đối với các hệ thống lớn.
Để giải quyết vần đề này, tôi thấy cần phải sử dụngmột ngôn ngữ lập trình để tạo SQL code. Hãy cùng xem chúng ta có thể sử dụng thư viện nào cho việc này.
pypika
pypika là một thư viện python giúp xây dựng câu lệnh SQL.

Tuy rất linh hoạt trong việc xây dựng câu lệnh SQL, pypika chỉ thuần túy hỗ trợ việc viết câu lệnh sql chứ không hướng tới việc cấu trúc toàn bộ câu lệnh sql trong doanh nghiệp.
Các điểm tôi thấy pypika chưa phù hợp với mục đích của mình.
- Không có hàm phục vụ load dữ liệu từ một file json
- Field của table được gọi ra như là một string của table, hoặc được sử dụng rời rạc chứ không phải là một class attribute trong table.
- Cấu trúc join hoàn toàn rời rạc với các table đã tạo.
Nhìn chung pypika chỉ phụ hợp với việc xây dựng câu lệnh SQL bằng python chứ không giúp cho việc cấu trúc lại các câu lệnh SQL về một nguồn thống nhất.
“ETL” model
Ở các phần trước bạn đã nghe thấy một model nằm trong một file json.
Tôi lấy ý tưởng từ lookml model của Looker. Tuy nhiên lưu ý rằng file này nằm ở tầng ETL thay vì tầng data model như lookml nên sẽ có đôi chút khác biệt.
Cấu trúc của file sẽ bao gồm:
table — là bảng dữ liệu, trong table bao gồm:
- field: dimension, measure — các chỉ tiêu tổng hợp như count, sum…
- condition: điều kiện filter bảng tương ứng.
join: chưa thông tin join giữa các bảng.
function: chứa các function được áp dụng chung ở trong database.
Một file model dạng đơn giản sẽ có dạng:
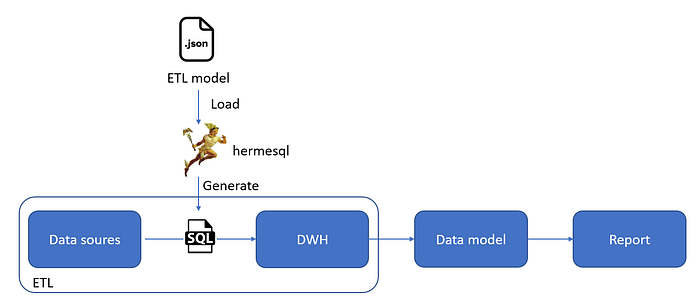
hermesql
hermesql là thư viện tôi phát triển dựa trên pypika. hermesql kế thừa khả năng xây dựng câu lệnh SQL của pypika kèm theo một số chức năng để phù hợp với mong muốn của tôi.
- Load các table, join và function từ một file json.
- Field được cấu trúc như là class attribute của table.
- Query có chứa connection để query vào database và lưu vào một file sql để nó được execute bởi các phần mềm ETL.
Việc sử dụng hermesql sẽ có dạng

SQL vs non-SQL data modeling

Nếu bạn quen thuộc với Looker hoặc Holistic, các bạn sẽ thấy hermesql giống một phiên bản đơn giản của data model layer của hai phần mềm này.
Cá nhân tôi quen thuộc với việc sử dụng Power BI — non SQL data modeling và không có ý kiến về sự khác biệt hoặc ưu nhược điểm của 2 cách tiếp cận này.
Tình huống sử dụng
hermesql không sử dụng ở tầng data model, bởi ở đó các tool bi đã làm rất tốt. Dù cho tool bi đó sử dụng cách tiếp cận SQL hay non-SQL.
hermesql được sử dụng ở tầng ETL bởi data engineer để họ thể quản lý và cấu trúc code dễ dàng hơn.