Cách hiệu quả đề truyền đạt kiến thức về machine learning
--

Sau một thời gian học và tìm hiểu về machine learning, cá nhân tôi nhận ra rằng có một số cách hiệu quả để truyền đạt kiến thức về ML cho người mới bắt đầu.
Cá nhân tôi cũng thấy hơi kì lạ khi các kiến thức về machine learning được giảng dạy khá khó hiểu ở hầu hết các khóa học trong khi những người dạy hoàn toàn biết về những công cụ tốt hơn để truyền đạt kiến thức.
Lưu ý rằng bạn ở các phần dưới bạn sẽ không nhìn thấy sự xuất hiện nhiều của toán. Điều này không có nghĩa toán học không quan trọng. Cá nhân tôi thấy cách tiếp cận và biểu diễn toán học cũng rất đẹp. Nhưng nó khá khó hiểu với nhiều người. Vì vậy tôi lựa chọn sử dụng những cách tiếp cận có vẻ đẹp dễ hiểu hơn với đại đa số.
“If you’re not having fun, you’re not learning. There’s a pleasure in finding things out” — Richard Feynman
Cách tiếp cận từ trên xuống
Đối ngược với cách tiếp cận từ dưới lên, tức là người học cần có các kiến thức về toán, thống kê ... Sau đó xây dựng từng bước các hàm số, tính đạo hàm từ đầu ... để ra được thuật toán. Cá nhân tôi thấy cách tiếp cận từ trên xuống mang lại nhiều hứng thú hơn cho người học.

Cách tiếp cận từ trên xuống được hiểu đơn giản là người học sẽ được nhìn toàn bộ quy trình và kết quả trước. Sau đó, họ sẽ được tìm hiểu dần và sâu hơn ở các phần tiếp theo.

Lấy ví dụ như để diễn giải logistic regression, ban đầu tôi sử dụng hàm sẵn có của sklearn để chạy và trình bày kết quả của thuật toán.
Sau đó, tôi mới triển khai từ đầu với từng block riêng biệt để giải thích sâu hơn về thuật toán.
Biết về từng bước trong thuật toán: Debug
Các bạn lập trình viên chuyên nghiệp khá quen thuộc với debug. Trong khi những người làm về phân tích dữ liệu lại khá xa lạ với khái niệm này.
Debug là quá trình tìm kiếm ra lỗi hay nguyên nhân gây ra lỗi (bug ở đâu) để có hướng sửa lỗi (fix bug). Để làm điều này, chúng ta cần đi từng bước của thuật toán, kiểm tra giá trị từng biến trước và sau khi thực hiện câu lệnh... Đây là những thao tác rất phù hợp để hiểu các thuật toán của machine learning.
Hãy quay lại với ví dụ về logistic regression ở bên trên.

Hiểu về cách thực hiện của thuật toán: hình ảnh hóa
Theo cá nhân tôi, cách tốt nhất để hiểu về thuật toán là hình ảnh hóa.
Ví dụ như cách thử các giá trị coefficient và intercept để tìm ra được điểm mà tại đó giá trị loss là nhỏ nhất (giả định rằng chúng ta chưa có kiến thức gì về gradient descent).

Ở trên màu càng đậm chứng tỏ giá trị loss càng cao, màu càng nhạt chứng loss càng thấp.
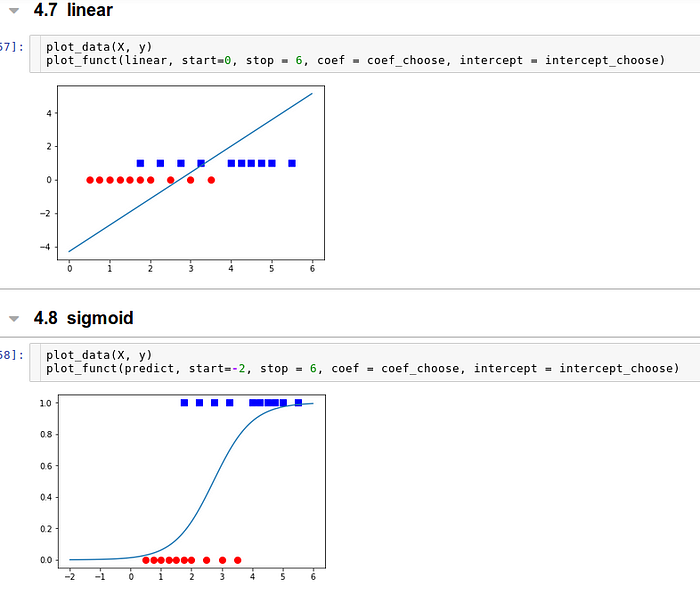
Sự thay đổi trong kết quả của hàm số khi áp dụng linear rồi activation function.
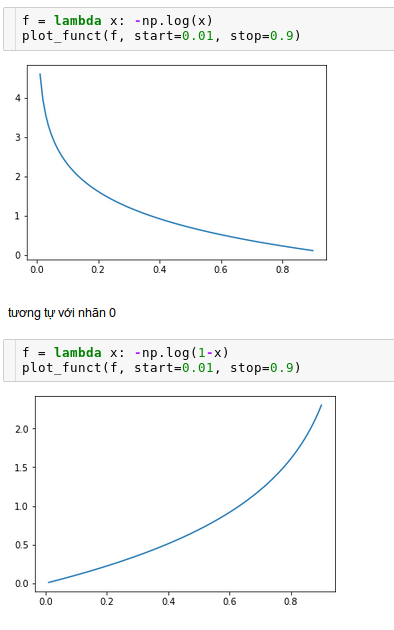
Lý do tại sao cross entropy loss lại có dạng -np.log(y_p) if y_t == 1 else -np.log(1-y_p)
Tạo cơ hội để người học tương tác
Cá nhân tôi cho rằng việc khiến người học hiểu những gì được dạy là chưa đủ. Để họ có thể áp dụng những gì đã học thì cần tạo cho họ nhiều cơ hội hơn để tương tác với các nội dung của bài học.
Ví dụ hàm learner của phần logistic regression được thiết kế để có thể thay đổi dữ liệu đầu vào, loss function và activation function. Người học sau khi đã hiểu thuật toán được khuyến khích thay đổi các yêu tố này, kết hợp với debug và hình ảnh hóa để theo dõi sự thay đổi trong kết quả dự đoán.

Tiếp theo là gì?
Một trong những vấn đề tôi nhận thấy ở nhiều khóa học về ML đó là người dạy cô lập người học trong vào một mục tiêu rất nhỏ của machine learning - tối thiểu hóa hàm mục tiêu. Sau nhiều buổi học, người học biết nhiều hơn về các kĩ thuật ML hiện đại nhưng nhiệm vụ của họ cần phải giải quyết vẫn không thay đổi.
Những người mới học thường không nhận ra sự cô lập này. Vì vậy khi họ học xong một khóa học và trở về với những vấn đề của doanh nghiệp thì họ lại hỏi lại câu hỏi: "tiếp theo tôi phải làm gì?"
Việc liên hệ giữa bài toán thực sự trong tổ chức và các bài toán trong machine learning là một phần tôi thấy nhiều khóa học không dạy. Trong khi theo tôi đây là một trong những phần quan trọng nhất. Tôi đã có viết một chút về chủ đề này tại đây.
