Làm thế nào để chọn tập kiểm định (validation set) tốt
--

Phân chia training set/validation set là một trong những bước quan trọng nhất của một dự án machine learning. Để làm điều này chúng ta thường sử dụng các thư việc có sẵn để phân chia ngẫu nhiên 2 tập dữ liệu này dựa trên một tỉ lệ nào đó. Ví dụ như với gói sklearn của python.
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.33, random_state=42)Tuy nhiên, việc ngẫu nhiên phân chia training set và valid set là một ý tưởng tồi. Thêm nữa, phân chia valid set mà không quan tâm tới test set còn khiến mọi chuyện tệ hơn nữa. Hãy cùng xem kĩ hơn lý do tại sao.
Vai trò của mô hình và từng tập dữ liệu
Training set
Training set bao gồm dữ liệu đầu vào và nhãn. Với training set, mô hình có thể nhìn thấy cả dữ liệu và nhãn. Nó sử dụng dữ liệu này để tối ưu loss function thông qua việc điều chỉnh parameter.
Validation set
Validation set cũng có dữ liệu giống như traning set. Nhưng mô hình không hề nhìn thấy nhãn. Mô hình đơn thuần dùng dữ liệu đầu vào của validation set để tính toán ra output. Sau đó nó so sánh với nhãn để tính loss function. Parameter hoàn toàn không được điều chỉnh ở bước này.
Validation set là bộ dữ liệu để chúng ta giám sát mô hình. Chúng ta sử dụng kết quả của mô hình ở training set và validation set để đưa ra các quyết định như điều chỉnh hyperparameter, bổ sung thêm dữ liệu...
Mô hình cần phải dự đoán tốt ở validation set. Tức là nó phải làm tốt với những dữ liệu mà nó chưa từng nhìn thấy.
Test set
Test set chỉ có dữ liệu đầu vào mà không có nhãn. Nó giống như những dữ liệu đến từ tương lai mà cả mô hình và chúng ta đều không biết được kết quả. Hiệu quả của mô hình khi dự đoán test set là thước đo xem mô hình có thực sự tốt trong thực tế hay không. Nếu mô hình chỉ làm tốt ở training set và validaiton set mà không tốt ở test set thì việc sử dụng mô hình trong thực tế không có nhiều ý nghĩa.
Hãy cùng dừng lại một chút xem chúng ta gặp vấn đề gì ở đây. Mô hình không thể làm gì nhiều. Nó chỉ có training set để học. Nhiệm vụ của nó chỉ là tối ưu loss function ở training set. Nó không thể học với validation set và test set. Vì vậy việc giúp cho mô hình làm tốt hơn ở cả validation set và test set phụ thuộc nhiều vào người training. Hãy xem anh ta/chị ta có thể làm gì.
Tính chất của validation set
Bài toán hồi quy
Ví dụ chúng ta có data set như bên dưới.

Nếu chúng ta phân chia ngẫu nhiên dataset này thành training set và validation set. Hình dưới là training set sau khi phân chia.
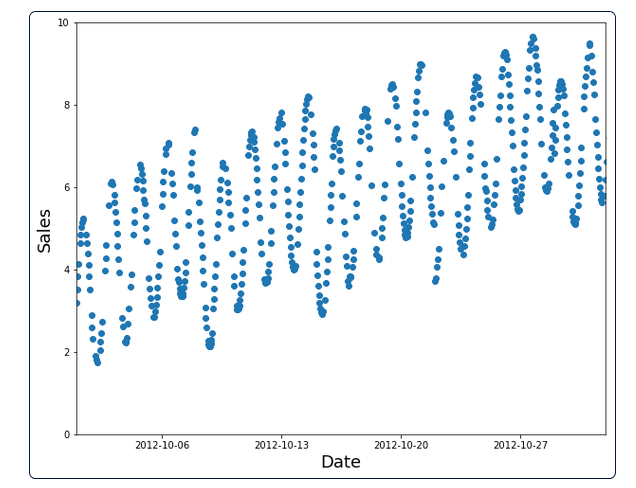
Rõ ràng đây là sự lựa chọn tồi. Bởi với training set này mô hình đã phần nào nhìn thấy toàn bộ dữ liệu, nhìn thấy cả dữ liệu tương lai của validation set trong quá khứ.
Mô hình sẽ làm tốt ở cả training set và validation set. Nhưng lý do phần lớn bởi nó đã nhìn thấy quá nhiều dữ liệu. Nếu dùng mô hình để dự đoán test set, chúng ta sẽ không chắc nó có làm tốt hay không. Bởi chúng ta không hề biết mô hình có dự đoán tốt với những dữ liệu mà nó chưa từng nhìn thấy hay không.
Ở bộ dữ liệu trên, cách phân chia đúng đó là chọn dữ liệu trước một khoảng thời gian làm training set, còn lại là validation set. Hình dưới mô tả training set.
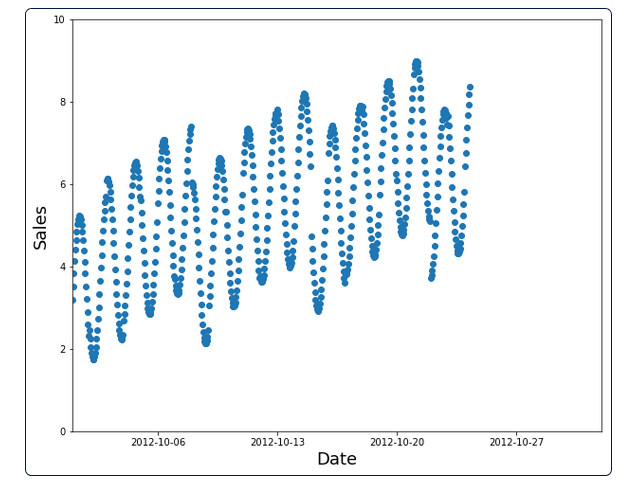
Bài toán phân loại
Giả sử chúng ta cần dự đoán xem một người có đang nghe điện thoại trong khi lái xe hay không. Chúng ta có 2 bức ảnh của cùng một người.

Sẽ thế nào nếu một bức ở training set, bức còn lại ở validation set? Điều này không có nhiều ý nghĩa. Bởi hai bức ảnh này khá giống nhau. Nếu mô hình làm tốt ở training set, thì nó cũng sẽ làm tốt ở validation set. Việc để những dữ liệu giống nhau ở cả training set và validation set sẽ không giúp chúng ta biết mô hình có làm tốt với những dữ liệu mà nó chưa từng nhìn thấy hay không.
Tính chất của validation set
Như vậy chúng ta thấy rằng, validation set cần phải có những dữ liệu không có trong training set để đánh giá khả năng dự đoán của mô hình với những dữ liệu nó chưa nhìn thấy. Validation set giúp chúng ta biết được mô hình có thực sự "học" hay chỉ là ghi nhớ từng trường hợp cụ thể.
Thêm nữa, validation set cần phải giống với test set. Tức là giống với dữ liệu thực tế trong tương lai. Điều này có vẻ phi lý vì dữ liệu tương lai không tồn tại ở thời điểm hiện tại. Chúng ta thường quen thuộc với sự xuất hiện của test set ở các cuộc thi về ML như kaggle. Tuy nhiên tư tưởng thì vẫn tương tự như trên. Mô hình cần phải dự đoán tốt với những trường hợp mà nó và cả người training chưa từng được quan sát.
Sai lầm thường gặp khi phân chia dữ liệu
Phân chia ngẫu nhiên
Cách này giống với việc sử dụng hàm train_test_split của sklearn. Như trên các bạn có thể thấy, việc phân chia ngẫu nhiên khiến chúng ta không thể kiểm soát được dữ liệu của training set và validation set có trùng lặp hay không hoặc không kiểm soát được training set có chứa dữ liệu ở thời điểm tương lai so với validation set hay không.
Sử dụng cross validation
Sử dụng cross validation thực ra cũng là chia ra thành k-fold ngẫu nhiên. Vì vậy kĩ thuật này cũng không nên dùng. Nhìn chung, các kĩ thuật lấy ngẫu nhiên khiến chúng ta rất khó kiểm soát được validation set có khác biệt so với training set và có tương tự với test set (ở các cuộc thi như kaggle) hay không. Việc sử dụng các fold ngẫu nhiên cũng khiến chúng ta khó gỡ lỗi mô hình hơn.
Kinh nghiệm xây dựng validation set khi thi đấu kaggle
Chúng ta không hề biết nhãn dữ liệu của test set khi thi đấu trên kaggle. Tuy nhiên, chúng ta biết được điểm số khi submit kết quả của mình. Vì vậy một mẹo nhỏ để biết validation set (của chúng ta) và test set của kaggle có tương đồng hay không đó sau mỗi lần submit, chúng ta biểu diễn validation score và kaggle score bằng scatter plot. Nếu các điểm số cùng nằm trên một đường thẳng tức là validation set khá tương đồng với test set.
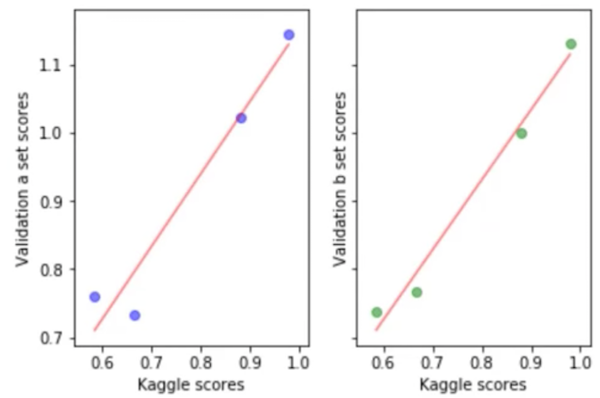
Ví dụ về thuật toán đơn giản để phân chia dữ liệu
Ở phần này tôi sử dụng bộ dữ liệu application train của cuộc thi Home Credit Default Risk để làm ví dụ.
Thuật toán khá đơn giản. Đầu tiên tôi chọn các biến liên tục và các biến phân loại của dữ liệu. Lưu ý ở đây ta có app_train_keep là dữ liệu có nhãn. Chúng ta cần chia tách dataframe này thành training set và validation set.
Một cách "ngây thơ", tôi chọn distinct các cách kết hợp của biến phân loại ở test set xem nó có tồn tại nhiều ở app_train_keep hay không.
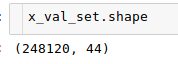
Cũng khá nhiều.
Sau đó trong số này, tôi chọn khoảng 20% ngẫu nhiên của từng nhóm khác biệt của các biến phân loại. Lưu ý rằng ở hàm random_choose, khoảng 20% cơ hội là nó sẽ lấy toàn bộ chứ không chỉ lấy 20%. Vậy nên sẽ có những cách kết hợp của biến phân loại chỉ có ở validation set mà không có ở training set.
Phần được chọn này sẽ là validation set. Còn phần không được chọn sẽ được đưa trở về x_trn để gộp thành training set. Chi tiết hơn các bạn có thể xem ở notebook tại đây.
Nguồn tham khảo
